TensorFlow Dropout
Introduction
When training neural networks, one of the most common challenges is overfitting - where a model performs well on training data but fails to generalize to new, unseen data. Dropout is a simple yet incredibly effective regularization technique introduced by Geoffrey Hinton and his team that helps combat this problem.
In this tutorial, you'll learn:
- What dropout regularization is and how it works
- How to implement dropout in TensorFlow
- Best practices for using dropout
- Real-world applications of dropout
What is Dropout?
Dropout is a regularization technique that randomly "drops out" (sets to zero) a number of output features from a layer during training. Each neuron is kept with a probability p and dropped with probability 1-p. This prevents neurons from co-adapting too much - forcing the network to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
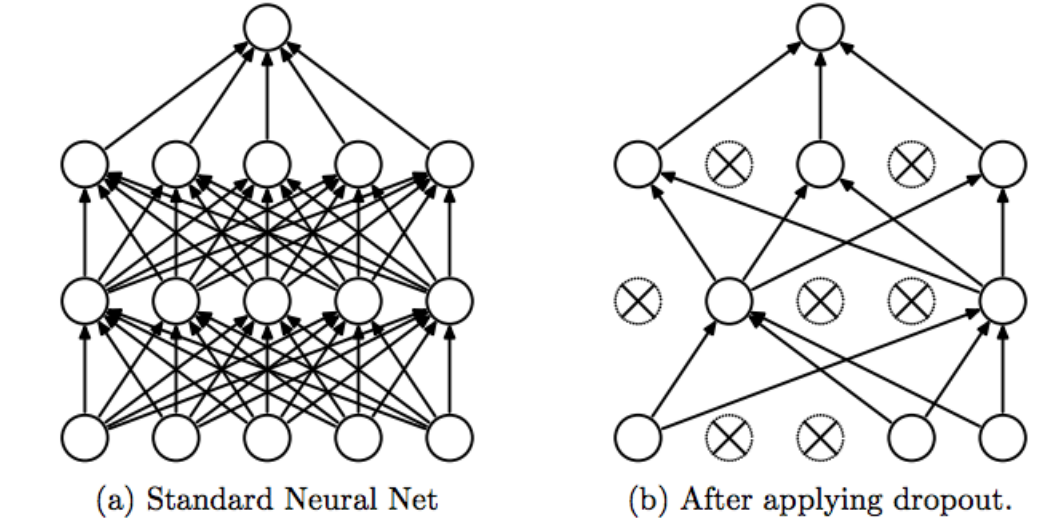
Implementing Dropout in TensorFlow
TensorFlow makes it incredibly easy to add dropout to your neural networks through the tf.keras.layers.Dropout layer.
Basic Syntax
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None)
The main parameters are:
- rate: Float between 0 and 1. Fraction of the input units to drop.
- noise_shape: 1D tensor of shape representing the shape of the binary dropout mask.
- seed: A Python integer to use as random seed.
Simple Example
Let's start with a simple neural network example that includes dropout layers:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# Create a simple model with dropout
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dropout(0.2), # 20% dropout rate
Dense(64, activation='relu'),
Dropout(0.3), # 30% dropout rate
Dense(10, activation='softmax')
])
# Compile the model
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# Model summary
model.summary()
Output:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 100480
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 8256
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 109,386
Trainable params: 109,386
Non-trainable params: 0
_________________________________________________________________
Understanding Dropout Behavior During Training vs. Inference
An important aspect of dropout is that it behaves differently during training and inference (testing):
- During training: Neurons are randomly dropped out based on the specified rate.
- During inference: No neurons are dropped, but the weights are scaled appropriately to account for more neurons being active.
TensorFlow handles this automatically for you! During training, the Dropout layer will randomly set input units to 0 with a frequency of rate. During testing, the Dropout layer does nothing - it just passes the input through unchanged.
Complete Training Example with MNIST
Let's see a complete example using the MNIST dataset:
import tensorflow as tf
import matplotlib.pyplot as plt
# Load and preprocess the MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # Normalize pixel values
# Reshape the data
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
# Create two models: one with dropout and one without
def create_model(use_dropout=False):
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dropout(0.2) if use_dropout else Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dropout(0.3) if use_dropout else Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
# Create and train a model with dropout
model_with_dropout = create_model(use_dropout=True)
history_with_dropout = model_with_dropout.fit(
x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2,
verbose=1
)
# Create and train a model without dropout
model_without_dropout = create_model(use_dropout=False)
history_without_dropout = model_without_dropout.fit(
x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2,
verbose=1
)
# Plot training & validation accuracy for both models
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history_with_dropout.history['accuracy'], label='With Dropout (Training)')
plt.plot(history_with_dropout.history['val_accuracy'], label='With Dropout (Validation)')
plt.plot(history_without_dropout.history['accuracy'], label='Without Dropout (Training)')
plt.plot(history_without_dropout.history['val_accuracy'], label='Without Dropout (Validation)')
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history_with_dropout.history['loss'], label='With Dropout (Training)')
plt.plot(history_with_dropout.history['val_loss'], label='With Dropout (Validation)')
plt.plot(history_without_dropout.history['loss'], label='Without Dropout (Training)')
plt.plot(history_without_dropout.history['val_loss'], label='Without Dropout (Validation)')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.tight_layout()
plt.show()
# Evaluate both models on the test set
test_loss_with_dropout, test_acc_with_dropout = model_with_dropout.evaluate(x_test, y_test, verbose=0)
test_loss_without_dropout, test_acc_without_dropout = model_without_dropout.evaluate(x_test, y_test, verbose=0)
print(f"Test accuracy with dropout: {test_acc_with_dropout:.4f}")
print(f"Test accuracy without dropout: {test_acc_without_dropout:.4f}")
When you run this code, you'll typically observe:
- The model without dropout tends to overfit more quickly (training accuracy increases faster than validation accuracy)
- The model with dropout usually has better generalization performance (better test accuracy)
- Without dropout, the gap between training and validation accuracy tends to be larger
Best Practices for Using Dropout
Here are some best practices to follow when using dropout in your neural networks:
1. Dropout Rates
Typical dropout rates range from 0.2 to 0.5:
- Input layers: Lower rates (0.1 - 0.3)
- Hidden layers: Medium rates (0.3 - 0.5)
- Output layer: Typically no dropout (or very low)
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dropout(0.2), # Lower rate for layers closer to input
Dense(256, activation='relu'),
Dropout(0.4), # Higher rate for middle layers
Dense(128, activation='relu'),
Dropout(0.3), # Adjust based on performance
Dense(10, activation='softmax') # No dropout before output
])
2. Combine with Other Regularization Techniques
Dropout works well in combination with other regularization techniques:
model = Sequential([
Dense(128, activation='relu', input_shape=(784,),
kernel_regularizer=tf.keras.regularizers.l2(0.001)), # L2 regularization
Dropout(0.3), # Dropout
Dense(64, activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)), # L2 regularization
Dropout(0.3), # Dropout
Dense(10, activation='softmax')
])
3. Adjust Learning Rate
When using dropout, you might need to adjust your learning rate or use more training epochs:
# When using dropout, you might need a slightly higher learning rate
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
4. Increase Network Size
Since dropout effectively removes neurons during training, you might want to use a larger network than you would without dropout:
# With dropout, you may want larger layers
model = Sequential([
Dense(256, activation='relu', input_shape=(784,)), # Larger than without dropout
Dropout(0.3),
Dense(128, activation='relu'), # Larger than without dropout
Dropout(0.3),
Dense(10, activation='softmax')
])
Spatial Dropout for CNN Models
For convolutional neural networks, TensorFlow provides spatial dropout, which drops entire feature maps instead of individual elements:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, SpatialDropout2D
# Create a CNN model with spatial dropout
cnn_model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
SpatialDropout2D(0.2), # Drops entire feature maps
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
SpatialDropout2D(0.3),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.4), # Regular dropout for dense layers
Dense(10, activation='softmax')
])
cnn_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
Real-World Application: Image Classification with Dropout
Let's implement a practical example of using dropout in a CNN model for the CIFAR-10 dataset:
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Load CIFAR-10 data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# Normalize pixel values
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# Create data augmentation generator
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True
)
datagen.fit(x_train)
# Create CNN model with dropout
model = Sequential([
# First convolutional block
Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)),
Conv2D(32, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
Dropout(0.25), # Dropout after first block
# Second convolutional block
Conv2D(64, (3, 3), padding='same', activation='relu'),
Conv2D(64, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
Dropout(0.25), # Dropout after second block
# Classification block
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5), # Higher dropout rate for fully connected layers
Dense(10, activation='softmax')
])
# Compile the model
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# Train the model with data augmentation
history = model.fit(
datagen.flow(x_train, y_train, batch_size=64),
steps_per_epoch=len(x_train) // 64,
epochs=20,
validation_data=(x_test, y_test),
verbose=1
)
# Evaluate the model
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"Test accuracy: {test_acc:.4f}")
In this real-world example, we've:
- Used dropout after each convolutional block
- Applied a higher dropout rate (0.5) in the fully connected layers
- Combined dropout with data augmentation for better regularization
- Created a model that should generalize well to new data
Summary
Dropout is a powerful regularization technique that can significantly reduce overfitting in your neural networks. In this tutorial, we've covered:
- The concept of dropout regularization and how it works
- How to implement dropout in TensorFlow using the
Dropoutlayer - Best practices for setting dropout rates and combining with other regularization techniques
- Using spatial dropout for convolutional neural networks
- A real-world application of dropout in an image classification model
Remember these key points:
- Dropout is only active during training, not during inference
- Typical dropout rates range from 0.2 to 0.5, with higher rates for larger networks
- Combine dropout with other regularization techniques for best results
- Adjust learning rates and increase network size when using dropout
Additional Resources and Exercises
Resources
- Original Dropout Paper by Hinton et al.
- TensorFlow Dropout Layer Documentation
- Regularization for Deep Learning (Chapter 7.12 of Deep Learning book)
Exercises
-
Experiment with dropout rates: Create a simple neural network for MNIST classification and experiment with different dropout rates (0.1, 0.3, 0.5, 0.7). Plot the training and validation accuracy curves for each rate and discuss the impact.
-
Dropout vs. other regularization: Implement a model with L2 regularization, a model with dropout, and a model with both. Compare their performance on a dataset of your choice.
-
Advanced dropout challenge: Implement a model with trainable dropout rates. Try using the concrete dropout implementation (hint: search for "concrete dropout TensorFlow").
-
Visualization exercise: Create a visualization showing the activations of a neural network with and without dropout. How does dropout affect the activation patterns?
By mastering dropout regularization in TensorFlow, you've added a powerful tool to your deep learning toolkit that will help you build more robust and generalizable models.
💡 Found a typo or mistake? Click "Edit this page" to suggest a correction. Your feedback is greatly appreciated!